Tablas de frecuencia
La forma más simple de hacer estadística es contar. Una tabla de frecuencias es una manera fancy de decir tabla de conteo por categorías.
Veamos a ver cómo se construyen tablas de frecuencia en R utilizando paquetes del tidyverse. ¡Listos para utilizar esto en el trabajo!
Primero vamos a convertir el conjunto de datos iris en un tibble y vamos a limpiar los nombres con janitor::clean_names(). La idea es que los nombre de las variables que cumplan con la guía de estilos del tidyverse. Si copias y pegas código más adelante, no olvides correr esto primero.
library(dplyr)
library(janitor)
iris <- as_tibble(iris) %>% clean_names()Tablas de frecuencia para variables cualitativas
Ahora sí, vamos a contruir la tabla de frecuencias para species.
iris %>%
group_by(species) %>%
summarise(frequency = n())## # A tibble: 3 x 2
## species frequency
## <fct> <int>
## 1 setosa 50
## 2 versicolor 50
## 3 virginica 50
En R utilizamos la n() para contar filas por grupos. Puedes ver más detalle en el artículo acerca de Encadenar operaciones en dplyr
Según este resultado, las tres categorías de la variable species aparecen 50 veces cada una. Y ya está, ahí tienes una tabla de frecuencias.
Graficar una tabla de frecuencias
Lo más fácil para visualizar una tabla de frecuencias es utilizar un gráfico de barras. Hacer este gráfico con ggplot2 es muy fácil
library(ggplot2)
iris %>%
group_by(species) %>%
summarise(frequency = n()) %>%
ggplot() +
geom_bar(aes(x = species, y = frequency), stat = 'identity')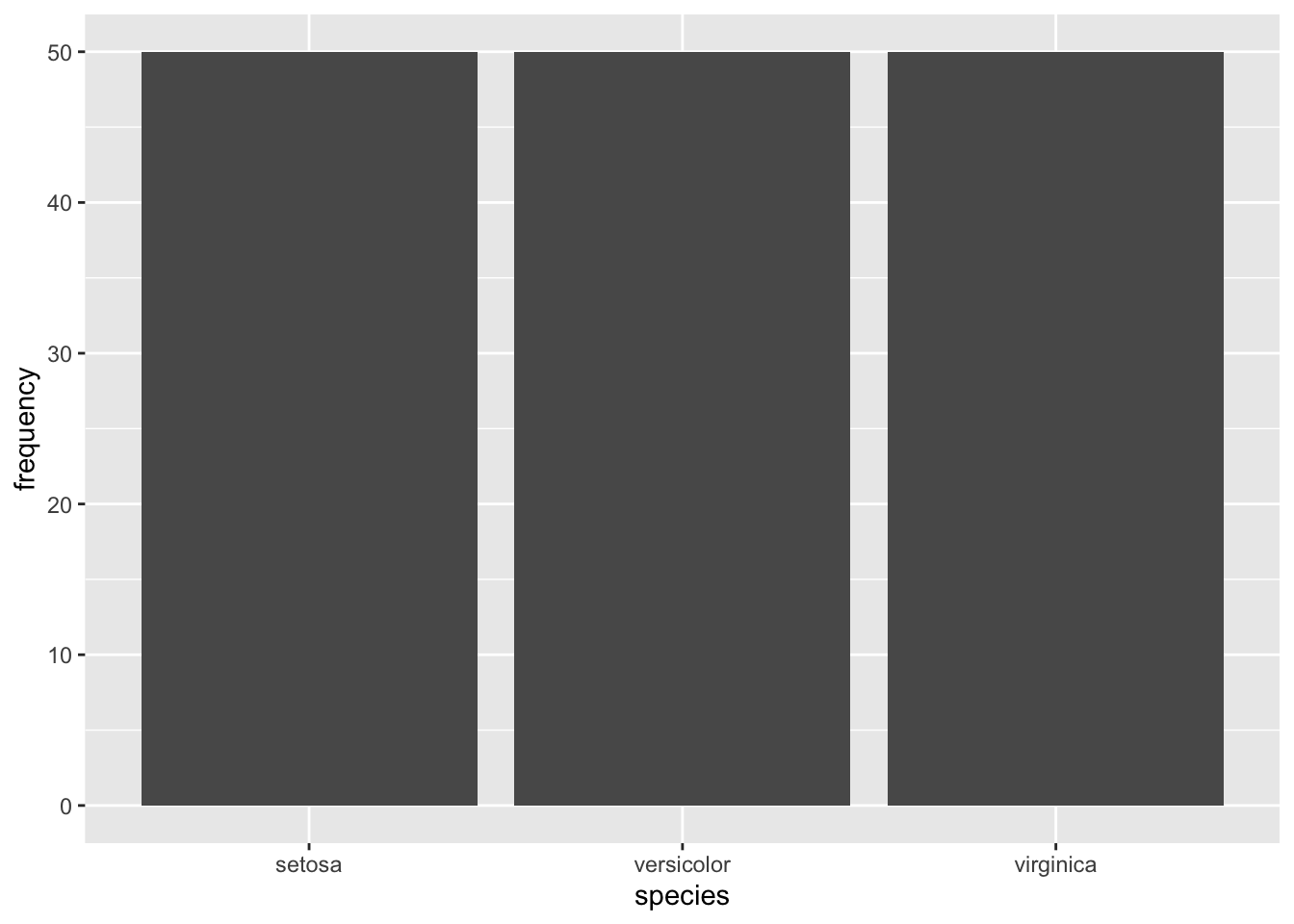
Pregunta
Si sumas todas las frecuencias ¿Qué resultado deberías tener?
- El tamaño de la muestra, n
- La suma de todos los valores de x
- No se puede saber
Pregunta
| Categoria | Frecuencia |
|---|---|
| Tipo 1 | 10 |
| Tipo 2 | 20 |
| Tipo 3 | X |
| Tipo 4 | 15 |
| n | 55 |
Tablas de frecuencia para variables cuantitativas
Supón que ahora quieres una tabla de frecuencias para sepal_length. Si sigues el mismo procedimiento, vas a terminar con un resultado prácticamente inútil.
iris %>%
group_by(sepal_length) %>%
summarise(frequency = n())## # A tibble: 35 x 2
## sepal_length frequency
## <dbl> <int>
## 1 4.3 1
## 2 4.4 3
## 3 4.5 1
## 4 4.6 4
## 5 4.7 2
## 6 4.8 5
## 7 4.9 6
## 8 5 10
## 9 5.1 9
## 10 5.2 4
## # … with 25 more rowsDos observaciones con respecto a este resultado:
- Hay 35 valores distintos para esta variable y leer una tabla tan larga no es práctico.
dplyrde hecho corta el resultado. Tendrías que usar alguna otra función comoView()para ver toda la tabla. - Puede ser más interesante agrupar valores cercanos, como 4.3 y 4.4; esta agrupación resuelve el punto 1 también.
Especificando el número de intervalos
Para agrupar valores de una variable cuantitativa en intervalos utilizamos la función cut. El procedimiento entonces queda como:
iris %>%
mutate(sepal_length_group = cut(sepal_length, breaks = 5)) %>%
group_by(sepal_length_group) %>%
summarise(frequency = n())## # A tibble: 5 x 2
## sepal_length_group frequency
## <fct> <int>
## 1 (4.3,5.02] 32
## 2 (5.02,5.74] 41
## 3 (5.74,6.46] 42
## 4 (6.46,7.18] 24
## 5 (7.18,7.9] 11¡El resultado es que tenemos 5 categorías en una tabla más legible!
Especificando los cortes o límites de los intervalos
Aunque el resultado anterior no tiene nada incorrecto, podríamos hacer que los intervalos sean más legibles. El truco es que el argumento breaks no sólo acepta el número de intervalos que queremos, sino que también podemos indicar los puntos en los que queremos hacer los cortes. Por ejemplo, vamos a hacer intervalos de longitud 1, desde el 4 hasta el 8. Esto lo podemos hacer con la función seq.
seq(from = 4, to = 8, by = 1)## [1] 4 5 6 7 8breaks <- seq(from = 4, to = 8, by = 1)
iris %>%
mutate(
sepal_length_group = cut(sepal_length, breaks = breaks)
) %>%
group_by(sepal_length_group) %>%
summarise(frequency = n())## # A tibble: 4 x 2
## sepal_length_group frequency
## <fct> <int>
## 1 (4,5] 32
## 2 (5,6] 57
## 3 (6,7] 49
## 4 (7,8] 12¡Mira qué linda tabla! A primera vista lo que se aprecia es que hay más valores bajos (entre 4 y 6) que altos (entre 6 y 8), y también que están más concentrados en el medio, (entre 5 y 6).
Los intervalos son abiertos a la izquierda y cerrados a la derecha. Esto implica que el 5 está incluído en el primer intervalo y no en el segundo
Frecuencias acumuladas
Podemos agregar una columna más a la tabla de frecuencias, acumulando las frecuencias para cada clase, utilizando la función cumsum.
breaks <- seq(from = 4, to = 8, by = 1)
iris %>%
mutate(
sepal_length_group = cut(sepal_length, breaks = breaks)
) %>%
group_by(sepal_length_group) %>%
summarise(frequency = n()) %>%
mutate(cum_frequency = cumsum(frequency))## # A tibble: 4 x 3
## sepal_length_group frequency cum_frequency
## <fct> <int> <int>
## 1 (4,5] 32 32
## 2 (5,6] 57 89
## 3 (6,7] 49 138
## 4 (7,8] 12 150Pregunta
| Categoria | Frecuencia | Frecuencia acumulada |
|---|---|---|
| (0 - 10] | - | 20 |
| (10 - 20] | - | 50 |
| (X - 30] | - | 80 |
| (30 - 40] | - | 100 |
- ¿Cuál es el tamaño de la muestra?
- ¿Cuál es la frecuencia del intervalo (10 - 20]?
- ¿Cuánto vale X?
Graficar una tabla de frecuencias de una variable cuantitativa
Podríamos seguir los mismo pasos que para una variable cualitativa y utilizar geom_bar
breaks <- seq(from = 4, to = 8, by = 1)
iris %>%
mutate(sepal_length_group = cut(sepal_length, breaks = breaks)) %>%
group_by(sepal_length_group) %>%
summarise(frequency = n()) %>%
ggplot() +
geom_bar(aes(x = sepal_length_group, y = frequency), stat = 'identity')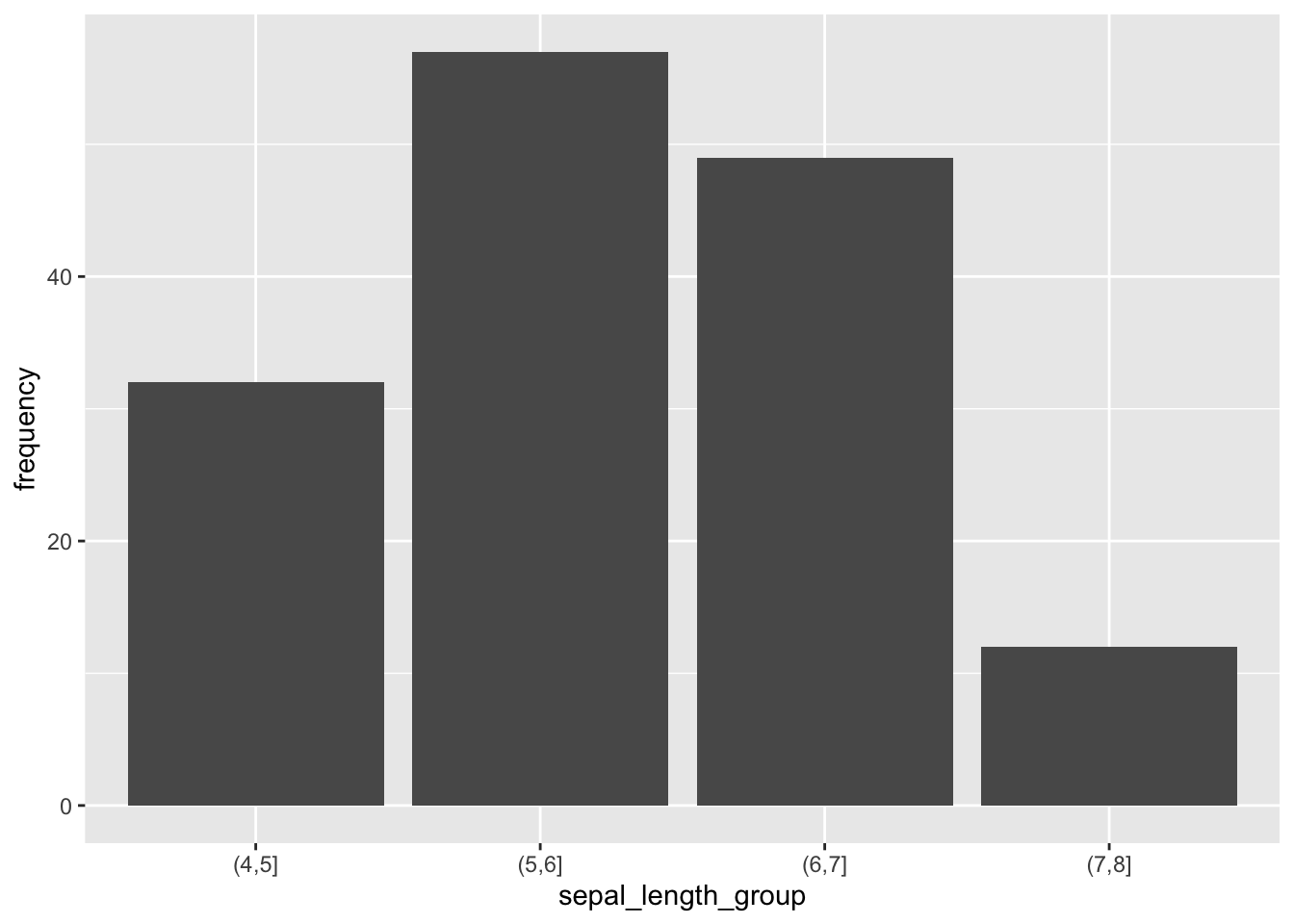
Sin embargo, un histograma es más apropiado. Un histograma es un tipo particular de gráfico de barras. Las principales diferencias son:
- Las etiquetas en el eje de las x se colocan los límites de los intervalos
- Si hay algún intervalo cuya frecuencia sea 0, este intervalo sigue mostrándose en el eje x, mientras que en un gráfico de barras no necesariamente
- Como el límite superior de un intervalo es el límite inferior del siguiente, no hay espacio entre las barras
- Las barras podrían tener anchos distintos, aunque esto no es muy común
- En el eje de las y siempre van las frecuencias. Si no, no es un histograma
Como los histogramas son gráficos muy comunes, existe la función geom_histogram para ahorrarnos algunas líneas de código.
breaks <- seq(from = 4, to = 8, by = 1)
iris %>%
ggplot() +
geom_histogram(aes(x = sepal_length), binwidth = 1, boundary = 4, colour = 'lightgrey')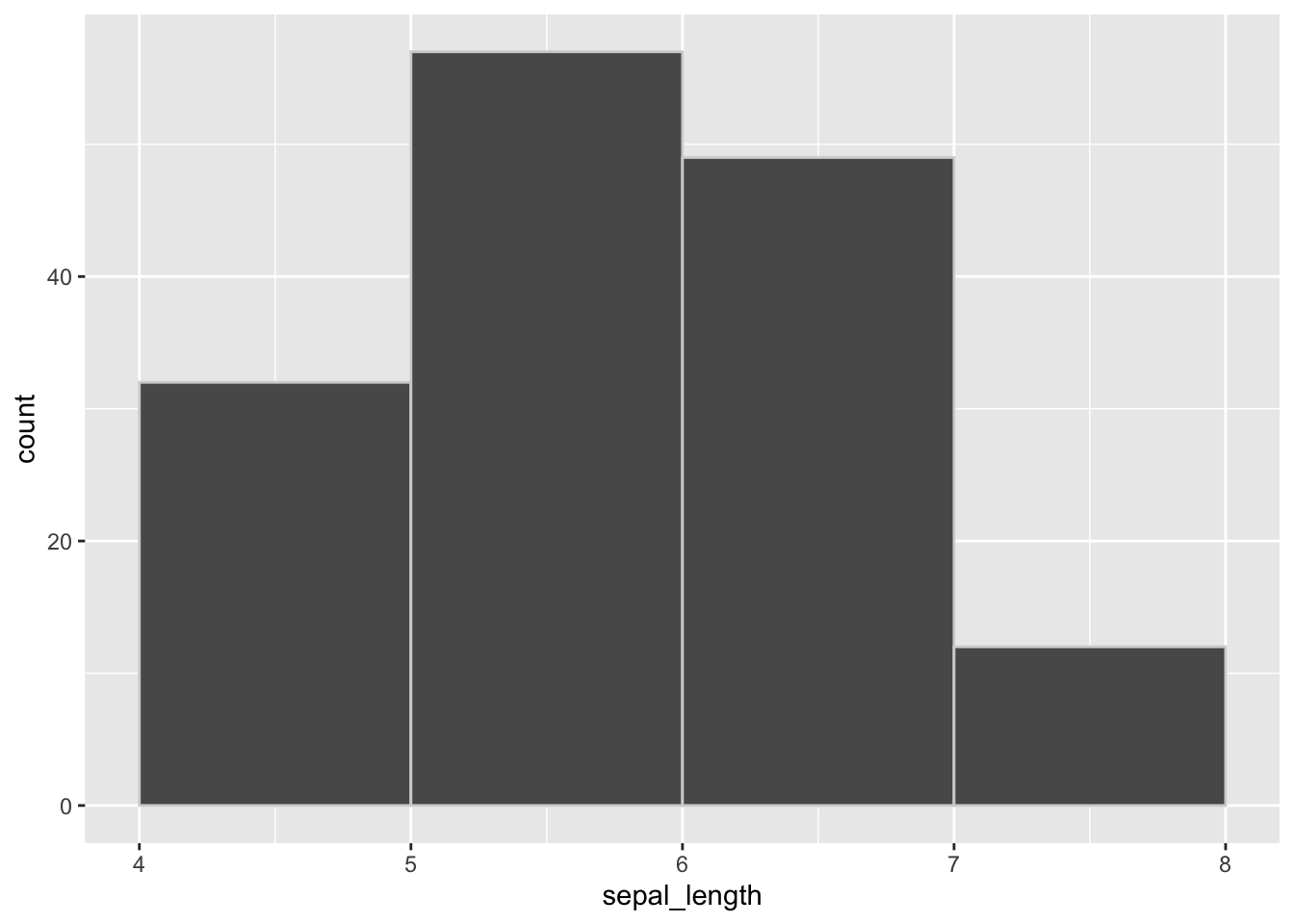
Para tener el mismo gráfico que antes, especifiqué que el ancho de los intervalos sea bidwidth = 1 y que uno de los límites sea boundary = 4. También agregué colour = 'lightgrey' para que los bordes fuesen gris claro; no es necesario, pero me gusta más cómo se ve así que sin separación entre las barras.
Ya que estamos viendo todo en un gráfico y no hay que leer, nos podemos dar el lujo de tener intervalos más cortos y por lo tanto más intervalos y más detalle.
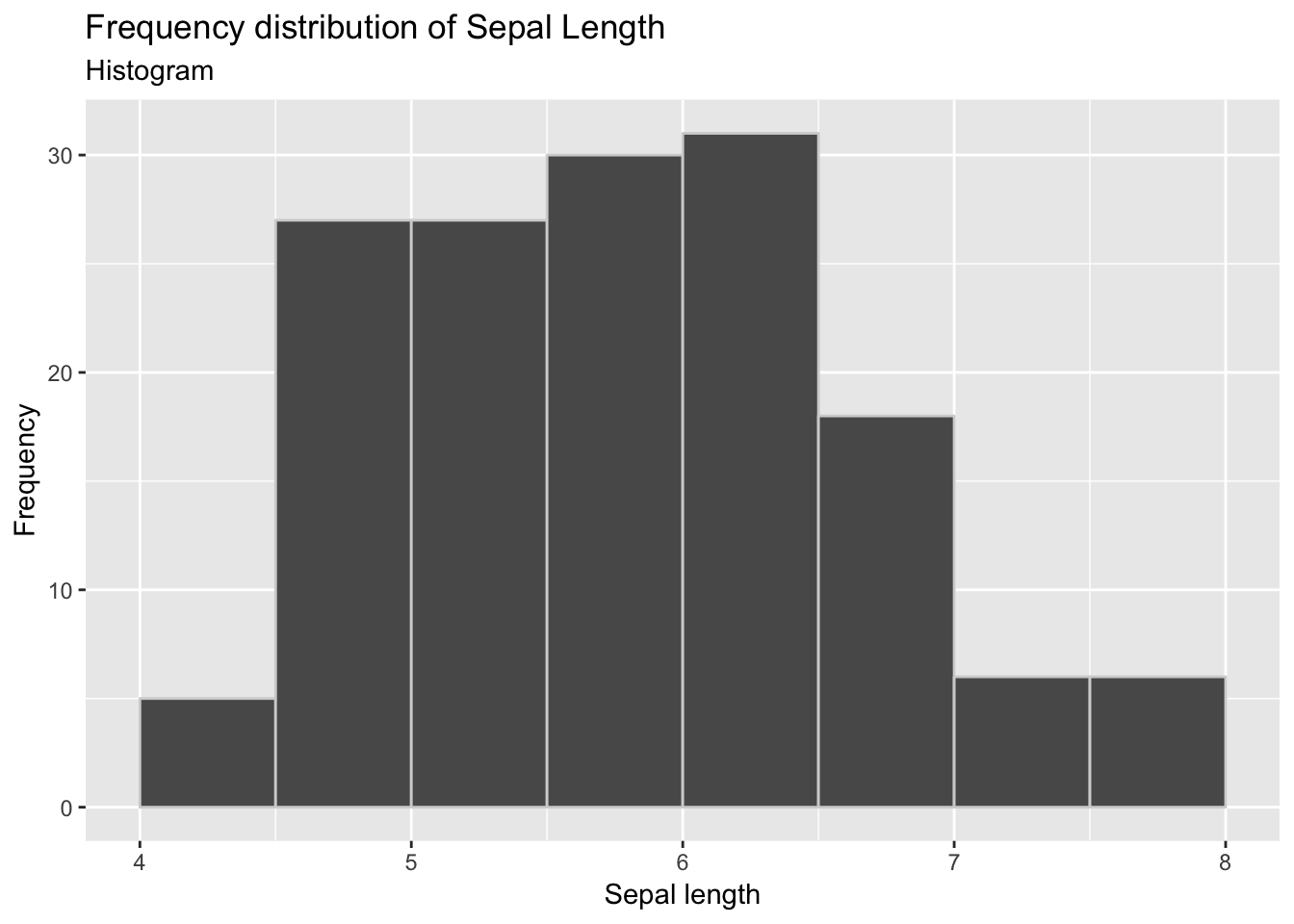
breaks <- seq(from = 4, to = 8, by = 0.5)
iris %>%
ggplot() +
geom_histogram(aes(x = sepal_length), breaks = breaks, colour = 'lightgrey') +
ggtitle('Frequency distribution of Sepal Length', subtitle = 'Histogram') +
labs(x = 'Sepal length', y = 'Frequency')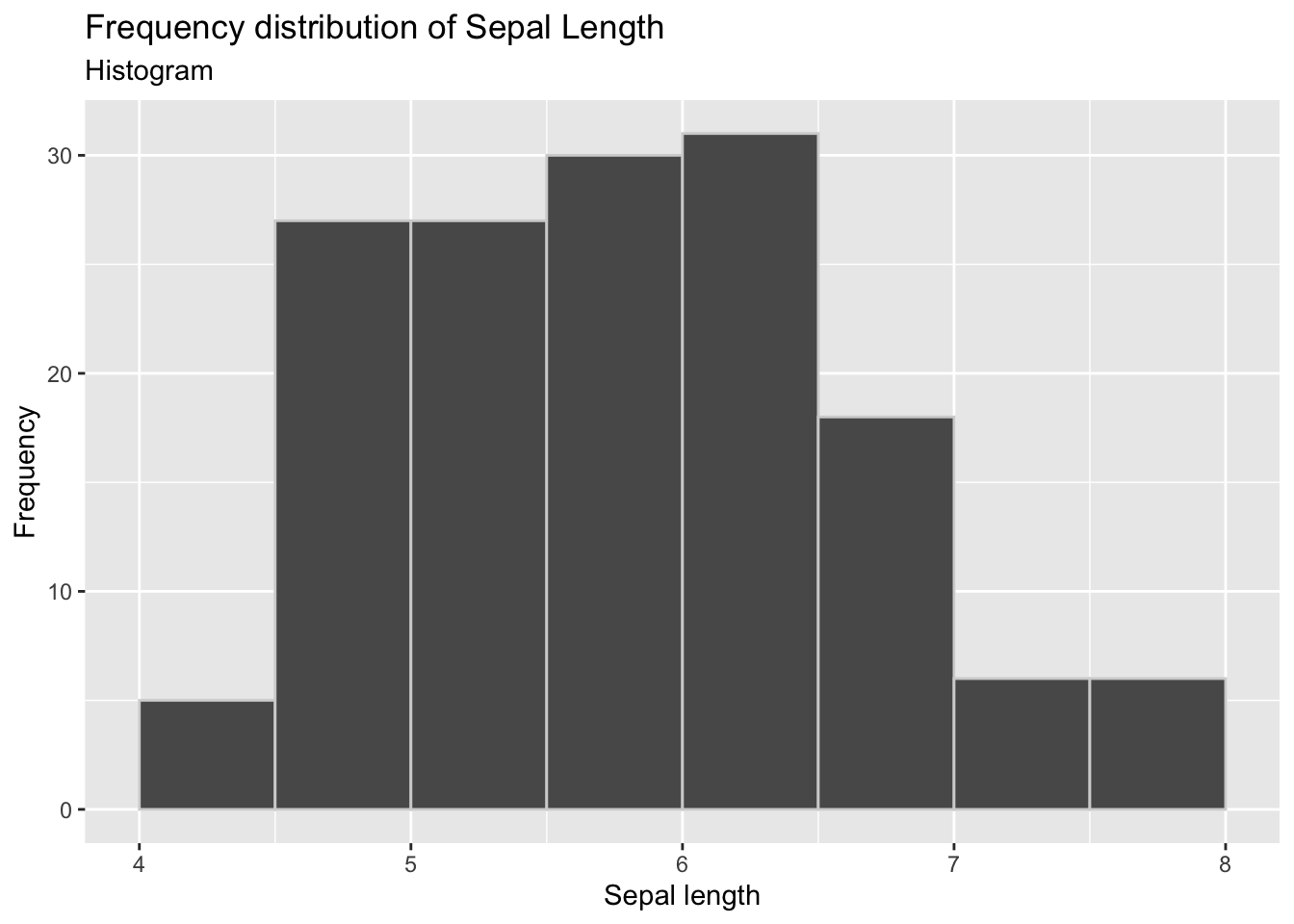
Conclusión
Las tablas de frecuencia son una herramienta bastante útil para saber de qué va una variable, y además se contruyen súper fácil en R. También vimos lo fácil que es visualizar las tablas con un gráfico de barras en el caso de una variable cualitativa y con un histograma en el caso de una variable cuantitativa.